Customer segmentations are a way for you to better understand your customer base by grouping them by traits.
In this post, as part of the Thoughts On series, we will dig more into what they are, why you might need them and how to construct them.
What are Customer Segmentations
The idea of customer segmentations are to divide, or segment, your customer base by common characteristics in order to better understand your customer. A segmentation allows you simplify the view of your customers and treat them as a few distinct personas instead of 100s or 1000s (or if you are lucky — millions!) of distinct people.
By turning your entire customer base into a handful of personas, or segments, you can more easily describe, analyse and build targeted strategies for each of your customers by focusing on a small set of personas.
This allow a level of “personalization” of your interactions with your customers without being truly personalized, ie unique to each customer. You can view segmentations as a medium level of granularity when it comes to personalized interactions. Here the least granular level is to consider all customers the same, equivalent to having just one customer segment, and the most granular is a truly personalized approach, where each customer is treated as unique, this is equivalent to having as many segments as you have customers.
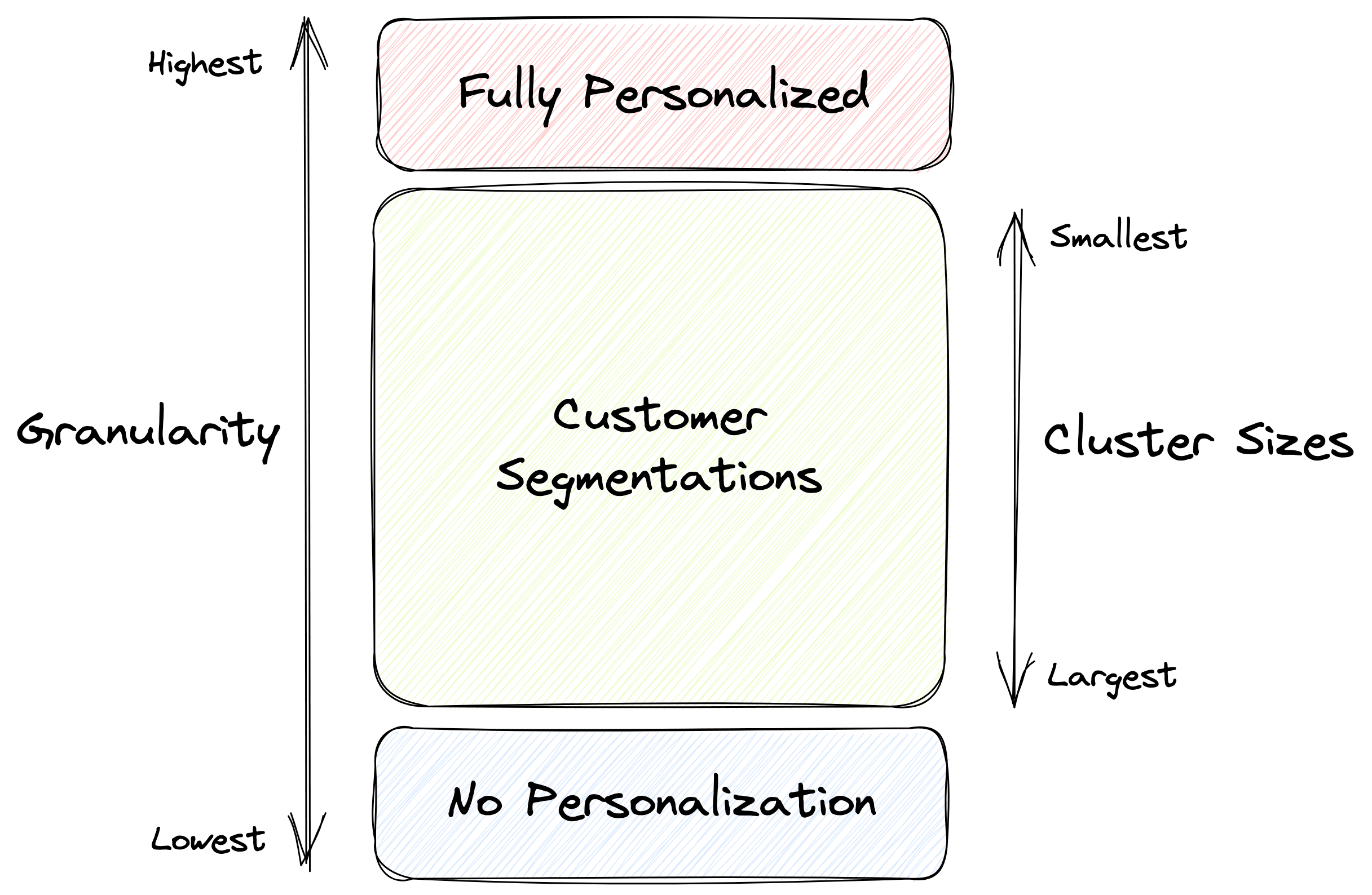
The level of granularity which you use depends on how you operate as a business and what the purpose of your customer segmentation is. If the aim is to build a personalized recommendation system within your product, ie something unique to the individual customer, then you are operating at the most granular level.
On the opposite end of the scale, if you are looking to build an overarching business strategy then you are most likely working with a single ideal customer persona (ICP) as your target. In this case you are at the lowest level of granularity — you want to characterize all your users, or your set of ideal users, as a single entity.
In between the two extremes, if you are working on a go-to-market or product strategy you probably want to feature some level of personalization in your strategy, to make them more targeted and effective, but obviously not at the individual level. This is where you need your customer segmentation in order to divide your customer base into well-defined sub-groups that you can then build your strategy around.
The level of granularity, ie the number of segments, that you want in your customer segmentation depends on the use case, but you typically aim to define between 3-8 segments.
Why do you want them
As mentioned, the purpose of customer segmentations are to be able to develop more targeted approaches to your users, be it in marketing, product, operations or sales, without becoming too low-level.
With a good customer segmentation you can build targeted marketing campaigns, user acquisitions and GTM strategies, product strategies, customer support play books and so on — each focused on a particular customer segment. This means that you can be more detailed and targeted in your approach than with a single ICP.
A good segmentation of your customer base allows you to build KPIs and targets in your customer journey for each customer persona — making it more targeted.
Customer segmentations typically come in four variants, depending on the customer characteristics used to build them. You might only build one of these types of segmentations or you might build several of them - depending on your needs.
The four typical variants are:
- Demographic: This is the classic type of segmentations. Here we use demographic data to define our segments, such as gender, age, income, location, education, job function, job title, etc. This is often done for sales or marketing, where you want to target a specific demographic profile.
- Behavioural: Here we look at behavioural data, often captured via our product or similar customer interactions. For example, what items they have viewed, what they have bought, how active they are etc.
- Attitudinal (aka Aspirational): An attitudinal segmentation is about segmenting customers by their attitudes and lifestyles. Typically these are captured using surveys and questionnaires about personal values, attitudes and lifestyles.
- Needs-based: This type of segmentation overlaps with both behavioural and attitudinal segmentations but in this case we look specifically at the subset of data related to the needs of the customer, such as their need for a product to have a certain quality, delivery time, price, sustainable profile etc.
Although uncommon, you can mix groups of characteristics when building your segmentation. This could be aspirational characteristics mixed with demographics - to link customer demographics to attitudes - or behavioural characteristics with needs - to link customer in-product behaviour with their needs.
Once one or more customer segmentations have been build you will typically use these throughout your organisation. - not just within a single department. This ensures consistency across business units and teams. For example, you can now easily link the product strategy to the go-to-market strategy, the go-to-market strategy to the customer journey of the customer success team and so on, since they all use the same personas. In fact, you will often find that with time your customer segments will become part of the internal language of the organisation — everyone knows who and what “Persona A” is and will use it when discussing new features, campaigns or other initiatives.
Because these personas become so embedded and integral to your business, the cadence in which you tend to redefine them are often infrequent. For some companies that means only once or whenever the business substantially changes — for others it means once every 1 or 2 years.
Defining your Customer Segmentation
Building a customer segmentation follows a more or less standardized process, irrespective of which type of segmentation or method of construction you choose. In our version it has 6 steps and each step comes with a number of choices - like what type of segmentation to build, the number of personas you want, how you want to describe them and so on.
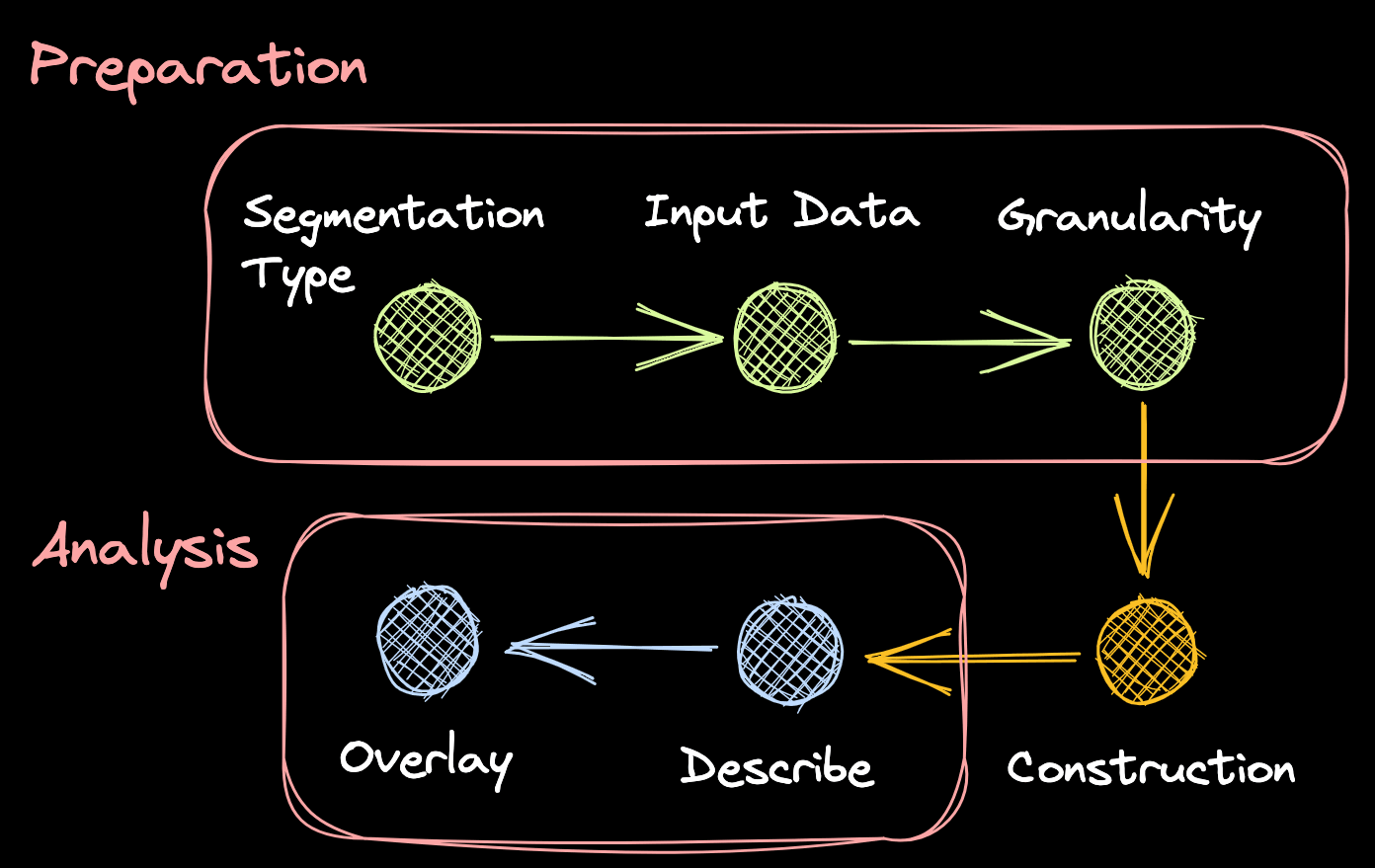
We will go through each of the steps here, explain some of the choices to be made and describe how each step is performed. The exact details of each step we leave to our example.
1. Define the type of segmentation
The first thing to decide on is the type of segmentation that you want to build. Are you looking to do a demographic, behavioural, attitudinal, needs-based or mixed segmentation?
The type of segmentation that you choose will define the rest of the process.
We have already described above each type and their motivation.
2. Define the input data
Having decided on a type of segmentation you want to do the next step is to evaluate what data you have available to support it.
The choice of data will shape the segmentation you create, so for each data column that you might include you need to ask ourselves
- If it matches your type of segmentation
- If you want our segments to be defined by it.
For example, if you want to do a demographic segmentation you should not include data about product usage, since that is behavioural, and you may have demographic data that you think is irrelevant, or inappropriate, to segment by, say location or ethnicity, so you exclude that as well.
3. Specify the number of segments
The final thing to decide on before you can start the construction of the segmentation, is how many segments you want to create — what we previously referred to as the granularity.
Note that depending on the method of construction this may not have to be an exact number but can be a range. In the case of SQL-inf you can either specify the minimum size of each segment or let it be determined by the algorithm.
You typically have two considerations when choosing the number of segments:
How many segments can your input data support? If your input data only has a small set of features to segment by, or if you only have a small set of customers to segment, you should pick a low number of segments. How many segments make sense from a usage perspective? Are you aiming to use this segmentation to build higher level strategies, then you want a lower number, or for more targeted marketing or product initiatives, then you may want a higher number of segments. We typically recommend a number between 3-8 where the exact number depends on the two above considerations.
4. Building the segmentation
There are generally two approaches to segmentation: rules-based and statistical.
In a rules-based approach the segments are pre-defined by a set of rules based on the values of the input data, irrespective of the input data itself — you could say it is a top-down approach.
In a statistical approach, on the other hand, the grouping of data into segments is based purely on the data itself. Here the segments are formed by detecting patterns in the data, applying statistical methods, and then grouping the data by these patterns. This could be described as a bottom-up approach.
Generally, statistical approaches are preferable to rule-based approaches, since they are data-driven in nature and do not rely on a “gut-feeling” to define the segments. In the case of SQL-inf, the CLUSTER function is a way to create a segmentation based on a statistical approach.

5. Describe each segment based on the input data
Once the segments have been defined the next step is to describe them by the data that defines them — this is how we make them relatable and build a compelling story about each segment. Often we do this by describing them as personas - a persona illustrates a segment by describing a typical member of the segment, as opposed to describing the segment using a set of statistics.
In the case of rule-based segmenting, the description of each segment is often purely based on the rules defining that segment but in the case of statistical segmenting we have to derive descriptions separately.
We do this by looking at the index, or propensity, of each feature in each segment versus the propensity in the overall population. This gives us a picture of how each segment is different from the average population. We can then use this to describe the segment. For example, if we find that a particular segment in a demographic segmentation is predominantly millennials and is 200% more likely to contain millennials than the overall data set, we can describe this segment as a “millennial segment”. What we are doing here is describing the segment using data points that are over-indexed compared to the overall population in a statistically significant way. This sets the segment apart from the other data. We call this type of analysis a descriptive, or count-based, approach to describing each segment.
To supplement this analysis we can also use a probabilistic approach to describing each segment. A probabilistic approach is performed by training a predictive model to predict which segment each data points belongs to. Once we have trained an accurate model to perform this task we can interrogate the model to understand how much each input determines whether a customer belongs to a certain segment or not. This is a more complicated analysis but it is often better than the descriptive approach at finding the best description for each segment.
With SQL-inf a probabilistic model can easily be trained and interrogated using the EXPLAIN commands.

6. Enrich your segments by including more data
Once we have derived the definitions of the segments we can overlay onto them the remaining data that wasn’t used as input data for building the segmentation. This allows us to expand our descriptions with a new set of statistics and persona traits.
To do this we can repeat either or both of the descriptive and probabilistic analysis from the step. The outcome is a secondary set of descriptions that, although they do no play a role in forming the segments, still add an extra layer of explanation to each segment.
7. Adding new data points
The final thing to understand is how you figure out which segment a new data point belongs to.
Again, in the rule-based approach this is easy. The rules define precisely which data points go where, so given a new data point you simply use the rules to find the segment that it belongs to.
For a segmentation build using a statistical approach it becomes a little more complicated. In this case, we use the techniques described in step 5 and 6 to assign segments to new data points, ie we build a probabilistic model to predict for a given data point which segment it belongs to and then we use this to assign the right segment to a new data point.
Again, in SQL-inf this can be easily be done using the PREDICT command.
That's all
That is it - that is all you need to know, and all the steps to follow, for you to create a great customer segmentation for your business and product teams.
The next step is to implement your customer segmentation!
However, if you need some more inspiration have a look at our example of how to implement a customer segmentation following the above steps and using dbt and SQL-inf to implement it.
